Transforming one CVE into two: studying a vulnerability on the cpp-httplib
In the first semester of 2025, Felipe Aníbal and I were part of the course MAC6988 - Cybersecurity, offered by the Department of Computer Science of the IME-USP. It was taught by Professor Fabio Kon in collaboration with Google’s office in São Paulo, with different professionals of the company taking part of the classes each week to teach us subjects they work in the industry, from compliance with the Brazilian law to more technical stuff, like Differential Privacy. It was a great experience!
One of our tasks at the end of the course was to present a recent CVE to the class, reproducing the chosen security flaw and explaining the proposed fix for it. The Common Vulnerabilities and Exposures (CVE) is a database archiving cybersecurity vulnerabilities, with a score system (CVSS) ranging from 0 to 10 for each report, 10 being a critical scenario. After a long search, we got ourselves facing the interesting CVE-2025-46728, which affects cpp-httplib and has a 7.5 score (high!). Our idea was to find a CVE and present it, but studying this one, we ended up creating a new CVE! This blog tells the story of how CVE-2025-53628 and CVE-2025-53629 came about.
Context
The cpp-httplib is a C++ open-source library that provides support for creating HTTP/HTTPS servers and clients. It’s cross-platform and very easy to use, as it’s just composed of a single header file. It’s published under an MIT license and actively maintained in its GitHub repository, which currently has around 15.6k stars and 2.6k forks.
Going a step back, what is HTTP? The Hypertext Transfer Protocol is one of the base protocols of the World Wide Web. It permits the transmission of hypertext documents, such as HTML, which is fundamental in our current way of using the internet. It’s an application-layer protocol based on the client-server model, and so, composed of two types of messages: requests and answers.
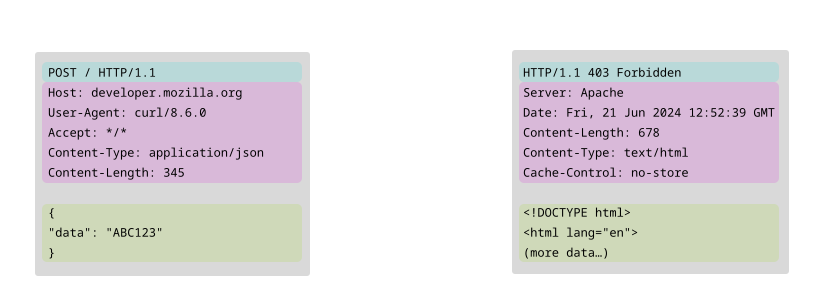
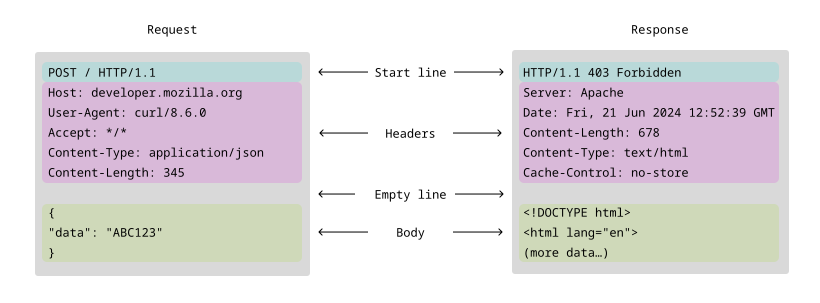 Anatomy of an HTTP request and answer. Image credits: MDN Web Docs
Anatomy of an HTTP request and answer. Image credits: MDN Web Docs
As represented in the image above, the structure of a HTTP packet is composed of: a start line, which contains the protocol version and the HTTP request method or the HTTP response status code; header lines, with useful information about the message; and, finally, the body, which carries the actual data.
Original CVE
One important line in the header of an HTTP request is the Content-Length one, present in the image above. It indicates the size, in bytes, of the body that comes right after the header section, allowing the other end of the communication to know how many bytes it must read before reaching the end of the message. Servers usually impose a maximum request body size and respond with a 413 (Payload Too Large) status code if a message doesn’t respect it.
However, what if we don’t know the final body size when writing the header? One solution proposed in HTTP/1.1 is to use chunked messages: you can split an HTTP message into small blocks (called “chunks”) and send them sequentially to the other end, keeping the connection open and warning it when the message is finished. To use it, one must substitute the Content-Length line with Transfer-Encoding: chunked and then send the body formatted in chunks: each one must start with its size in bytes, followed by a line break, and then the content of the chunk, which also ends with a line break. The last chunk must have a length explicitly equal to 0, indicating the end of the data.
The original vulnerability reported by Ville Vesilehto consisted of exploring this option: he discovered that cpp-httplib up to the version 0.20.0 failed to enforce a size limit to requests using the chunked format, allowing arbitrarily large messages that could lead the server to exhaustion of its resources. The proposed exploration of it was straightforward: the client should send an infinite number of chunks, never sending the final one with zero length. More details can be read in its advisory in GitHub’s library repository.
Exploring the flaw
The reporter made available a Proof of Concept (PoC) in order to test the vulnerability, providing a simple C++ client built using the cpp-httplib to answer requests on the localhost and a Python script to act like a malicious client. This last one explores the flaw by first sending the header of the message with the line Transfer-Encoding: chunked and then an enormous number of chunks, until the server stops answering, an indication of a successful Denial of Service (DoS).
We tested this “malicious” script against version 0.20.0 of the library and, as expected, the system killed the server’s process due to high memory usage. Against version 0.20.1, the fix got into action and closed the connection without any bigger impact, perfectly! Preparing ourselves for the presentation, we decided to take a look at the communication between the server and the client through Wireshark, and the content of the first packet caught our attention:
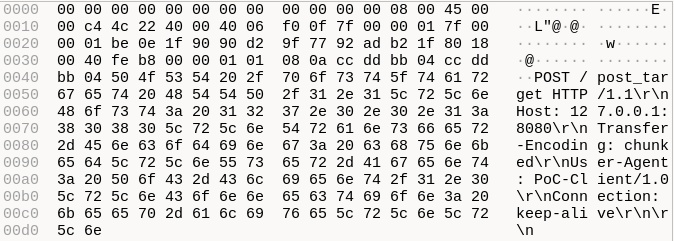 Wireshark view of the first packet of the communication using the original PoC script.
Wireshark view of the first packet of the communication using the original PoC script.
Why were there so many \r\n explicitly written? This is the representation of a CRLF character, or more simply, a line break. But why were they not being interpreted as a line break (which they are) and being displayed explicitly? Looking carefully at the PoC’s Python script, we would find this as the definition of the headers:
1
2
3
4
5
6
7
8
request_headers = (
f"POST /post_target HTTP/1.1\\r\\n"
f"Host: {TARGET_HOST}:{TARGET_PORT}\\r\\n"
f"Transfer-Encoding: chunked\\r\\n"
f"User-Agent: PoC-Client/1.0\\r\\n"
f"Connection: keep-alive\\r\\n"
f"\\r\\n"
).encode('ascii')
As we are building a header that will be encoded as simple ASCII, we truly want to explicitly write the line breaks, as they are important for the packet structure, delimiting each line. But note that each line break is written as \\r\\n, not simply \r\n. Accidentally, writing in this way, we end up scapping the backslash and getting the literal text \r\n, and not the line break character we would expect. This explains why we saw so many \r\n in Wireshark. But, as this behavior was present in the whole Python malicious script, we don’t have any true line break! The packet we were seeing is just a giant single line.
If we are not building the malicious packet in the correct way, why does the fix still work? The fix commit available in GitHub’s repo proposes exactly a limitation on the maximum length for each read line, getting to fix this flaw. But, if so, and what if we change the Python script to correctly break the lines, switching the \\r\\n to \r\n? The flaw persists! And, now, we observe that the packets are well interpreted in Wireshark:
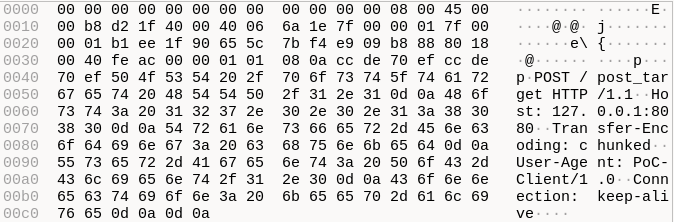 Wireshark view of the first packet of the communication, now using the adjusted PoC script.
Wireshark view of the first packet of the communication, now using the adjusted PoC script.
So, by mistake, the proposed commit ended up fixing another flaw: before it, the library didn’t enforce any limit for a unique line, permitting an attacker to also allocate memory arbitrarily by exploring it. However, the original vulnerability about packets encoded as chunks was still there.
Reporting our findings and concluding
We reported this unexpected behavior by writing an advisory in GitHub’s project repository, explaining it in detail. The proposed fix by the library’s maintainer now checks if the total length of the chunks exceeds the payload limit and also changes the return information of the functions responsible for reading the packets, making clear the disction between errors in the reading and packets that exceed the payload limit. In this way, version 0.23.0 of the library is also secure against huge chunked messages.
Therefore, the original CVE-2025-46728 that we found was decomposed into two new ones: CVE-2025-53628, which reports the absence of a unique line size limit; and CVE-2025-53629, which reports the problem with chunked packets. It was a fun journey!