Research checkpoint #03: a first attempt to understand the data
In the previous post, me and professor Daniel decided to already start to take a look at the CIC-IOT-2023 dataset, which is a great candidate for our tests. In the weeks I reported in that post, I focused on implementing baseline machine learning models to be able to evaluate how the modifications we will apply to the dataset will affect the information it can provide. One major point observed, however, was: how to work with this dataset? We have a lot of PCAP (Packet Capture) files, containing the observed traffic in the experiments conducted by the researchers who provided all this data, but how can we manipulate it? This is the question I’ve been dealing with these last two weeks.
Materials studied
The CIC-IoT-2023 is a dataset that contains a large amount of benign and malicious traffic from an IoT network, composed of 105 devices and with 33 different types of attacks performed. Together with it, the researchers from the University of New Brunswick also published an article reporting their work, explaining their methods to generate and collect all this data and even conducting some initial analysis using machine learning models:
E. C. P. Neto, S. Dadkhah, R. Ferreira, A. Zohourian, R. Lu, A. A. Ghorbani. “CICIoT2023: A real-time dataset and benchmark for large-scale attacks in IoT environment”, Sensor (2023) – (submitted to Journal of Sensors).
During the process to generate the ~548 GB of data, benign and malicious traffic were collected. To generate the benign, the network was observed during a period of 16 hours, with human interactions and also just idle. To the malicious, seven categories of attacks were performed:
- Distributed Denial of Service (DDoS) and Denial of Service (DoS) attacks: ACK and UDP fragmentation, Slowloris, flood with different protocols and Synonymous IP flood;
- Reconnaissance attacks: Ping Sweep, OS scan, vulnerability scan, port scan and host scan;
- Exploiting web-based vulnerabilities: SQL Injection, command injection, exploiting backdoors, uploading attacks, Cross-Site Scripting (XSS) and browser hijacking;
- Spoofing: ARP and DNS spoofing;
- Brute force attacks;
- Mirai as an IoT threat.
All the tools used to conduct these attacks are listed in the article, with a lot of more details on how each one of them were performed.
The article also explains the structure of the network they used for this experiments, with details of the IoT topology they deployed and with a list of the used devices. As attackers, they mainly used Raspberry Pi 4 devices.
The traffic data was collected using Wireshark and published as PCAP files. Also, the authors of this work published some CSV files, which are composed of features extracted from the PCAP files summarized by a fixed-size packet window. These files can be used as an easier way to train machine learning models, since their format are convenient and they also are structured with preselected features that represent well all the data. However, for our purposes, it would be good to deal with the packets individually, without considering them in fixed windows. They also shared the scripts used to generate these CSV files, and these scripts were what I was looking for.
Looking at the CIC-IoT-2023 dataset scripts
The authors of this dataset shared some python scripts that they used to generate the CSV files I mentioned above. They implement this pipeline:
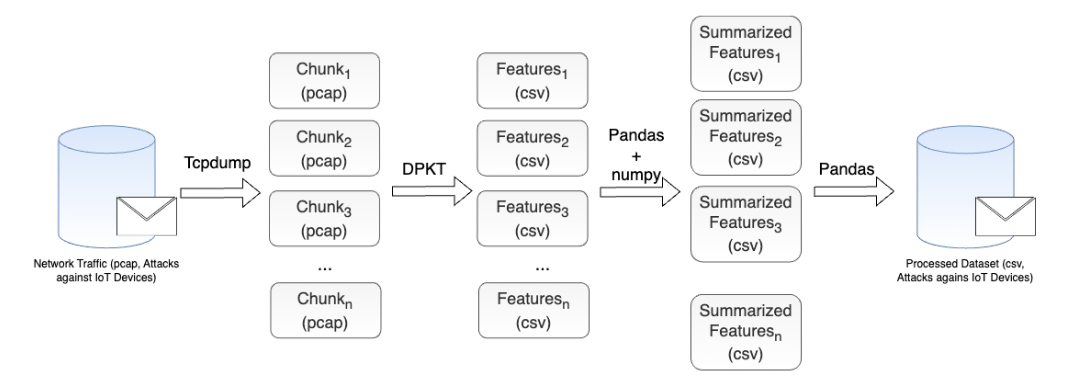 Process to convert the PCAP files to CSV. Image taken from the original CIC-IoT-2023 article, credits to the authors.
Process to convert the PCAP files to CSV. Image taken from the original CIC-IoT-2023 article, credits to the authors.
- First the data is partitioned into chunks using tcpdump, a command-line packet analyzer;
- Then, DPKT, a python module that provides tools to manipulate packets, is used to extract selected features (table 4 of the original article) and store them into temporary CSV files. They also perform a data cleaning in this stage, removing the incomplete entries, and also doesn’t import the timestamps;
- Using pandas and NumPy, they group the values in windows (10 or 100 packets depending on the attack) and calculate their summarized values;
- To finish the process, they combine the files to form an unique processed CSV file per attack (or more than one, in the case that the volume of data is big);
- For the ML analysis, the CSV files from different attacks are combined using PySpark, the python API for Apache Spark, which permits a large-scale data processing in a distributed environment.
I did some analysis of these scripts and I think that they can be easily used/modified for our purposes, that is converting the packets individually into CSV files, which will be processed using the feature engineering techniques that I’ve being studying and then by our ML models. These scripts also works with packets alone, with the window being of size one (some calculated values miss their purpose, but this doesn’t break the scripts), but I think we would lose a lot of performance using them in this way, since they weren’t designed for this use.
One last observation: one of our concerns expressed in the last posts in using this dataset was the timestamp, as it could make the data to be unintentionally classified by period and not by its purpose. However, this information can’t be removed without any processing, because the relative order of the packets is based on it, and also helps to find the streams of data. The scripts mentioned above deal with this in this way: they import the packets in the order they were received by Wireshark, keeping they sorted, and discard the timestamp value from the CSV files, as they don’t illustrate the network behavior. All the packets in the PCAP files also have a stream index in the transport layer, which is used to identify the streams of data, but I don’t know if we can import this information using DPKT, which would be useful for sorting the flows together in a future analysis. However, we probably still can find these streams just by looking at the IPs in the communication.
Next steps
For the next weeks, my plans are:
Get to understand clearly the use of the libraries and tools I cited in this post, and try to design the first scripts for the PCAP to CSV conversion.
Depending on the progress, work a little more in the baseline models code I wrote in the last post.
I finally exercised my studyings in Kaggle! At the PMR3508 discipline, we did an exercise that consisted in an initial data analysis of the Adult dataset, it was good to get my hands dirty. It would be good to keep practicing, specially with data from computer networks traffic.
This post was made as a record of the progress of the research project “DDoS Detection in the Internet of Things using Machine Learning Methods with Retraining”, supervised by professor Daniel Batista, BCC - IME - USP. Project supported by the São Paulo Research Foundation (FAPESP), process nº 2024/10240-3. The opinions, hypothesis and conclusions or recommendations expressed in this material are those of the author and do not necessarily reflect the views of FAPESP.