Research checkpoint #05: summarizing what we have so far
This project is about to complete three months of work and during this time my focus was in studying theoretical material specially related to how to handle with data, looking at some possibilities of datasets to use in this research, understanding how to work with network traffic, studying feature engineering and getting to know Python libraries that can help in our objectives. In this post, I report my studies from the last three weeks and also propose some ideas for the structure that will handle the packets in the network, focusing on the data preparation.
But first, a parenthesis: in the last post I discussed three different Python libraries that are capable of handling network packets, and besides them there are a lot of another libs that aim to make easier the work in computer networks context, like Twisted! It’s focus is different from the ones cited before, as this is an event-driven networking framework that provides a high-level API capable of deal with many different protocols. For this moment of the project it isn’t a necessary tool, but I decided to take a note about it here as it may be useful at some point. :)
Considerations about the network structure
As related in my first post about the project, our main objective with it is to understand which feature engineering, distributed inference and retraining techniques are the most efficient in the context of an machine learning based IDS for an IoT network. These three topics are approaches to different parts of a unique structure, which can be summarized as follows:
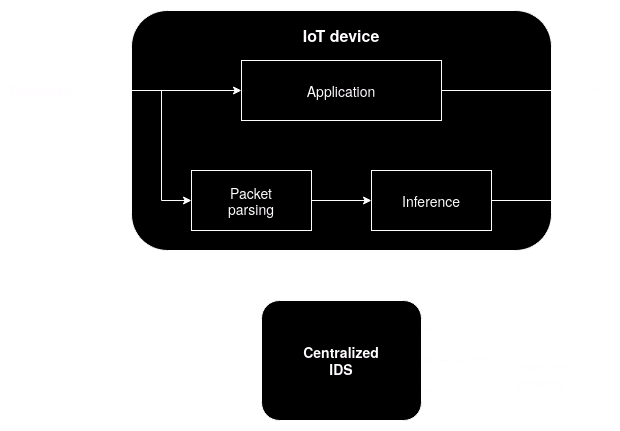
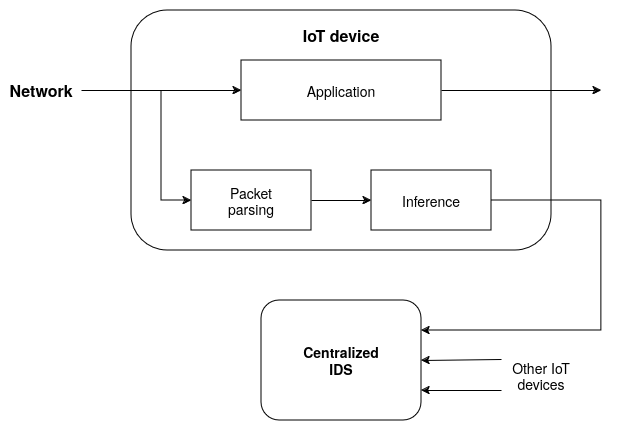 A proposal for the path of a packet through the IoT network
A proposal for the path of a packet through the IoT network
In the proposal above the process related to the IDS consists of three different phases:
Packet parsing
In this first phase, the packets are sniffed from the network traffic in the IoT device, without affecting the destination application of them, as we are just developing an detection system. This data needs to be converted for a suitable format for our model to work, and this is the moment when we also apply feature engineering techniques in order to improve the prediction performance, using the studies conducted so far.
During these first months of the project, this first phase has been my main focus of study and I already listed in the last post some Python libraries that can help in this job. Between them, dpkt presents the best execution time, but at the same moment it isn’t capable of doing the sniff for itself. However, there are another libraries that can do this job, like pypcap, which can work together with dpkt easily.
Inference
After the data is adjusted for our purposes, we want to distinguish if this a benign or malicious traffic invoking the model used as the IDS, aiming to detect DDoS attacks against the network. Notice that our proposal is to perform this inference directly in the IoT devices, process which we are calling as distributed inference, considering only its traffic.
One major concern we need to address is performance: realizing the packet parsing and the inference on the IoT devices will remove a big load of work from the centralized system, but at the same time can result in a overload of the device performing it now. Our proposal is to work with neural networks (NNs) and we have examples of use cases where it performs well with these kind of devices, but this assumption is true for all the models of NNs? And we will also need to perform the packet parsing before the prediction, how will these two phases affect its processing power that needs also to be shared with the user application running? We need to be careful on these choices, as the inference speed ideally can’t be slower than the network rate.
The choice of the NN model isn’t planned to be part of our study, as this is a broadly topic of discussion in articles, papers and in the literature of this field. But, we plan, in the end of the project, to try to study the explainability of the model.
Training
During all this process, a centralized system is planned to perform a continuous training of the machine learning model used as IDS, taking advantage of retraining techniques that will be studied further. In the current moment, we have a baseline model implemented that is already designed to be capable to perform this process, but other techniques will be studied addressing models that maybe work different from this one, like the logistic regression one used as the other baseline.
For the construction of all this structure, our idea until this moment is to use the CIC-IoT-2023 dataset to perform the initial training simulating an IoT network, as already cited in previous posts. The details of this process still need to be addressed, in the next section I will discuss more about how the data will be manipulated.
How to handle the traffic data
In both the training and packet parsing phases appointed above, we need to make choices about how to handle with the network traffic. There are two main possibilities under consideration:
Numerical approach
The most natural approach is to convert the packets to numerical data and use known well-performing neural networks to perform the evaluation of the data. In the next section, I relate my studies in a master thesis that used this approach and achieved excellent results, performing feature selection and using another feature engineering techniques.
In the thesis mentioned, the authors observed that shuffling the data during the training phase leaded to better results (they discussed this a way more deeply than this single affirmation), and this is an idea we already had some thoughts about: in the dataset we are considering to use, the benign and malicious data are separated in different PCAP files, how we can merge them to perform the training of the model? Should we shuffle them? If yes, how can we keep the flows grouped to not lose the logical sequence of the packets? One possible idea is to use a two-pointers technique: we read the files in their natural order and keep track of the last packet we chose to use in each of them; for the choice of the next packet to be sent to the emulated network, considering the next ones in each file, we use a fixed criterion, like a random choice or using the timestamp information. In this way, the final order of the packets would be shuffled, but not in relation to the original files.
Image approach
Another approach that has shown great potential is to convert the packets to images using some criterion and then use Convolutional Neural Networks (CNNs) to perform the prediction, as they have achieved amazing results in the field of computer vision. One recent paper that address this technique and propose some new ideas is “SeNet-I: An approach for detecting network intrusions through serialized network traffic images”, by Y. A. Farrukh, S. Wali, I. Khan and N. D. Bastian. On it, the authors demonstrate how CNNs can use the spatial information of images to extract some useful features automatically avoiding the heavily use of feature engineering, which is something difficult to reproduce in other classical methods with a more limited data representation.
One another interesting contribution from the article cited above is the use of a contiguous stream of samples to create one image and not a single packet, as this can potentially uncover anomalous behavior related to the temporal information without introducing bias to the model, such as using some ID information. In their final tests, they also observed that flow-based models (that utilizes only the network traffic metadata) performed better than packet-based (that uses the packet payload).
More materials studied
During this time, I also took a look at the Kétly Gonçalves Machado master thesis, named “Detecção de ataques DDoS no tráfego da IoT utilizando métodos ensemble para classificação de fluxos contínuos de dados” (in free translation, “DDoS attack detection in IoT traffic using ensemble methods to classify continuous data streams”), presented as final result of the Computer Science graduation program at IME-USP and supervised by the professor Daniel Macêdo Batista. This work helped me a lot to visualize how the initial analysis of data and the exploratory analysis can affect the performance of a model in our context of work. Two interesting topics mentioned that can be already considered in this project:
Balance of the dataset: the dataset we are considering to use has a great volume of benign traffic (close to 7GB of raw packets), however the volume generated by DDoS attacks is a way bigger than that. In this way, we need to be careful to not unbalance the data during the training phase. To generate more data to achieve balance, the authors of the thesis used the SMOTE technique (Synthetic Minority Over-sampling TEchnique), but this also needs to be done carefully, as the model can end learning to simply differentiate between authentic and synthetic data.
Correlation: for the feature selection, one good metric to be used is the Spearman’s rank correlation coefficient, capable of evaluate the individual correlation between two features.
Next steps
Considering the division of the network structure proposed here, our next steps in this project are:
- Packet Parsing
- Conduct experiments to verify the performance of Python libraries sniffing the network and processing the packages in a Raspberry Pi (different from what we did in post 4, in which we tested the lib’s with the CIC-IoT-2023 dataset and in a regular computer).
- Inference
- Run the baseline models proposed in post 02 in a Raspberry Pi to verify its performance.
- Training (centralized IDS)
- TBD.
Our intentions are to keep track of the points above across the next posts, updating them and checking our progress.
This post was made as a record of the progress of the research project “DDoS Detection in the Internet of Things using Machine Learning Methods with Retraining”, supervised by professor Daniel Batista, BCC - IME - USP. Project supported by the São Paulo Research Foundation (FAPESP), process nº 2024/10240-3. The opinions, hypothesis and conclusions or recommendations expressed in this material are those of the author and do not necessarily reflect the views of FAPESP.