Research checkpoint #11: publications and studying the generation of CSV files
As summarized in the introduction of post 10, in the last posts I described experiments we conducted evaluating the performance of a Raspberry Pi model 3B, a computer with limited processing power, in sniffing packets from network traffic and handling machine learning models, in order to further progress our studies on how to handle DDoS attacks on these clients. In the last months, our work has been to adapt these studies to papers, which have been submitted to two national events on the subjects we’re researching, more details in the next section of this post. We also performed more experiments, analyzing different ways of making live network traffic suitable for AI models, as described in the section “Studies on how to generate CSV files from network traffic”.
Submissions to events
Using our studies on the Raspberry Pi’s performance while sniffing packets from the network reported in posts 07, 08 and 09, me and professor Daniel Batista proposed the paper “Performance Evaluation of Python Tools to Capture Packets in Resource-Constrained Devices”, submitted to the WPerformance (“XXIV Workshop on Performance of Computing and Communication Systems”) event, a forum to discuss and disseminate ideas about methods, techniques and tools to evaluate the performance of computing and communication systems. This event is part of the 45º Brazilian Computer Society Congress (CSBC 2025), which will take place in Maceió - AL, Brazil, from July 20th to 24th. Our proposal was to evaluate the performance of three tools to capture packets in Python running on a limited performance computer, more details and all the code used in the work can be found in our GitHub repository. We’re currently awaiting the committee evaluation of the work.
In this same context, we decided to address one more research topic: which is the best way to generate useful data for ML models from the live network traffic to further perform inference on the packets? For this, we performed experiments on how to generate CSV files from the network packets. These experiments resulted in a publication: “Online Adaptation of Network Traffic Traces at Clients to Feed Intrusion Detection Systems”, submitted to the WTG event, a space where undergrad students have the opportunity to share their studies in the 43º Brazilian Symposium on Computer Networks and Distributed Systems (SBRC 2025), that will take place in Natal - RN, Brazil, from May 19th to 23th. All the code produced can be found in our GitHub repository, the next section reports more of our findings and how the experiments were conducted. We’re also currently awaiting the committee evaluation of the work.
Studies on how to generate CSV files from network traffic
Our main study subject in this research is how to detect DDoS attacks using machine learning (ML) models on low performance computers. However, how to generate the data that will feed the models is a fundamental question: we want to observe the network traffic passing through a device and be able to identify if it is benign or malicious, to detect intrusions, but how do we subject the packets to this evaluation? One method, adopted in the CIC-IoT-2023 dataset, is to sniff the traffic and save it as PCAP files, and then generate CSV files from them, which will be later analyzed by the model. However, can’t we simplify this process and rely less on disk? Our proposal with the experiments here is to generate the CSV files directly from the sniffed packets, not passing through an intermediary phase of PCAP files.
Two scenarios were considered for our experiments:
- For reference, the usual procedure: we collected the packets in the network, generated a PCAP file and then processed this file to produce a CSV;
- For comparison, we collected the packets and directly generated a CSV file from them.
To process the packets, coming both from the PCAP and directly from the sniffer, we used the CIC-IoT-2023 supplementary material scripts that are capable of producing this kind of file, extracting features from groups of 10 packets to produce each entry of the final CSV file. To the reference procedure, we used the Pyshark Python library to capture the packets in the network and generate the PCAP file; and for the experiments without an intermediary step, we used the Pypcap library to capture the packets, that were sent to the CIC scripts in two ways:
- In one battery of tests, the thread capturing the packets sends them to the other one that is responsible for generating the CSV file in batches of 10 packets;
- In the other, we send the packets all together after the sniffer has concluded.
For these experiments, we used Python threads, which are concurrent, so the packet processing isn’t happening in parallel in the current implementation. In the reference one, the CIC scripts split the PCAP files into smaller ones of 10MB and use different processes to work on them, naturally parallelizing this phase. We limited it to use at most 3 simultaneous processes.
To execute the experiments, a Bash script was used to orchestrate the procedure:
- Run the Python code in background and wait 20 seconds to ensure the sniffer is ready (25s in the case of Pyshark);
- Use iperf3 to generate a UDP data stream with a defined bit rate that lasts 10 seconds;
- Wait for the Python code to end its processing and end the experiment, reporting the performance metrics and deleting the output files.
The machines used for this experiment and the tools to collect the data were the same as the ones from the previous studies, which can be found in detail in post 07. Additionally, we used the psutil Python library to also measure the average of bytes read and written on disk, discussed in the paper. All the code used can be found in this project’s GitHub repository.
Summary of results
All the metrics obtained from the experiments are discussed in more detail in the published paper (in Portuguese). Below, I summarize our findings.
The baseline method we considered naturally never loses packets, as it is processing the data registered by the sniffer on a PCAP file. However, in our proposals without the intermediary file, we need to handle context changes to send the packets to the thread that is designed to process the data and produce the CSV file, which results in a significant loss. Notice also the high standard deviation in the next graph (indicated as a black line at the top of the bars): high bit rates generate inconsistency in the algorithm performance.
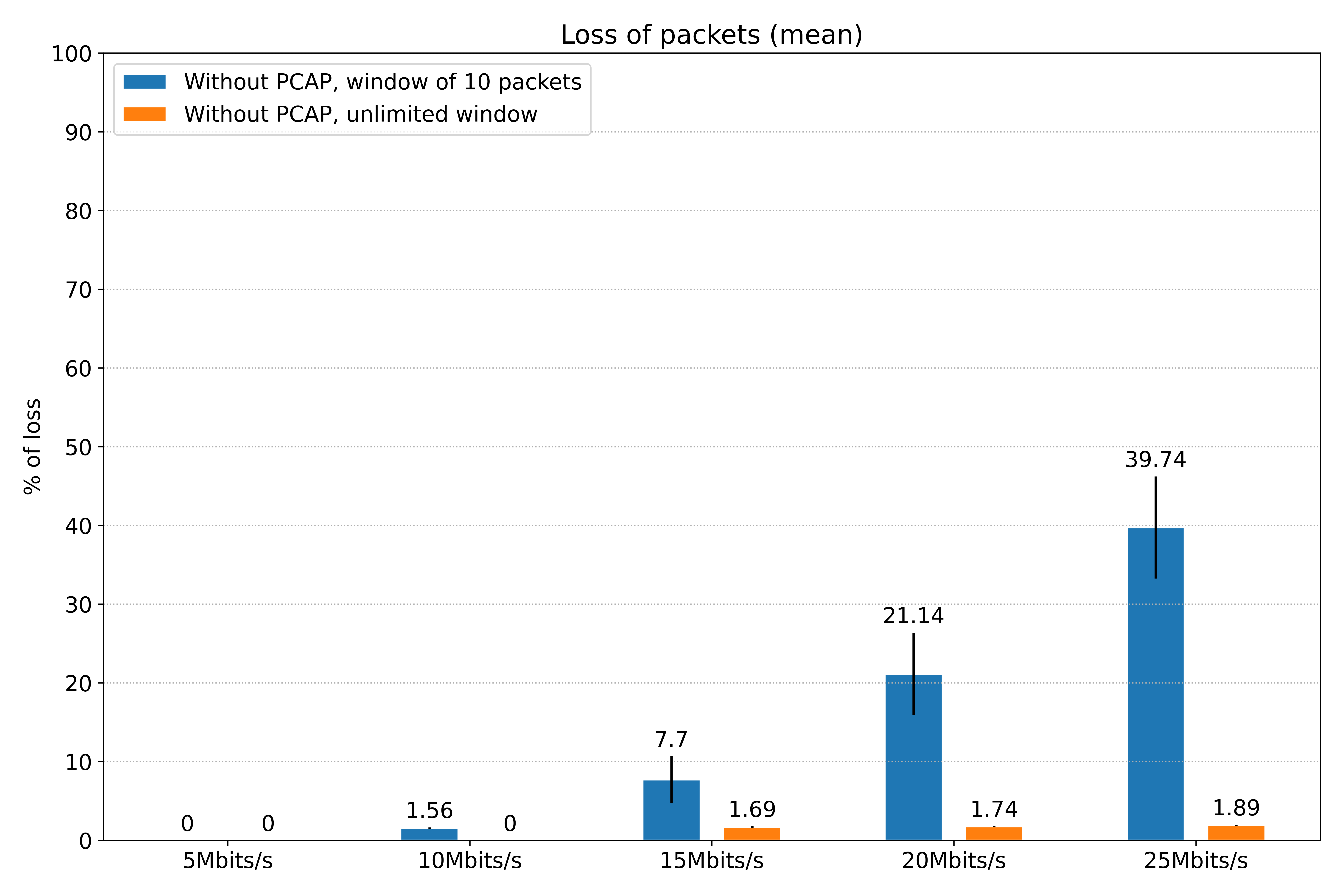 Percentage of packet loss. Obtained by comparing the number of lines of the final CSV with the number produced by the reference code.
Percentage of packet loss. Obtained by comparing the number of lines of the final CSV with the number produced by the reference code.
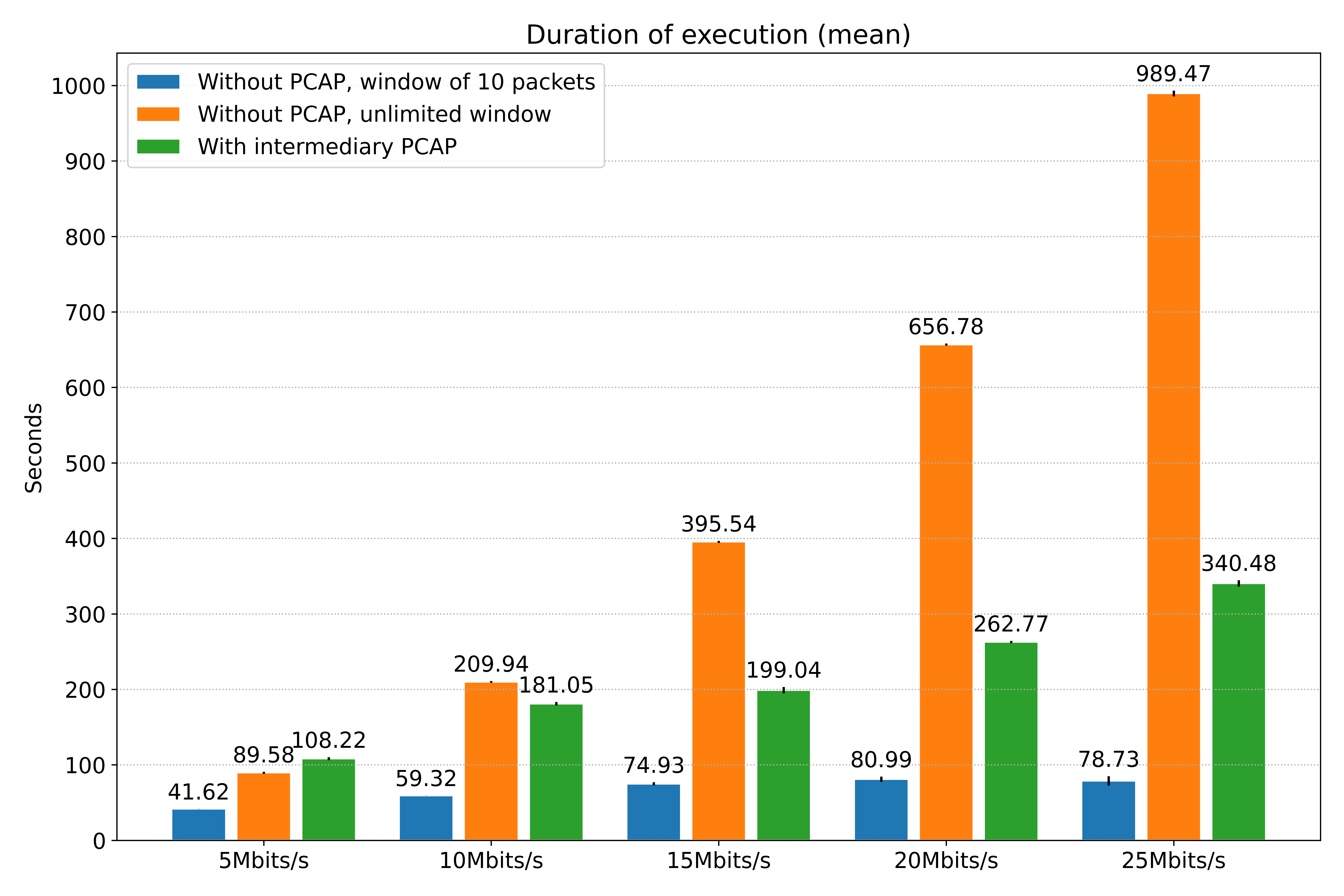
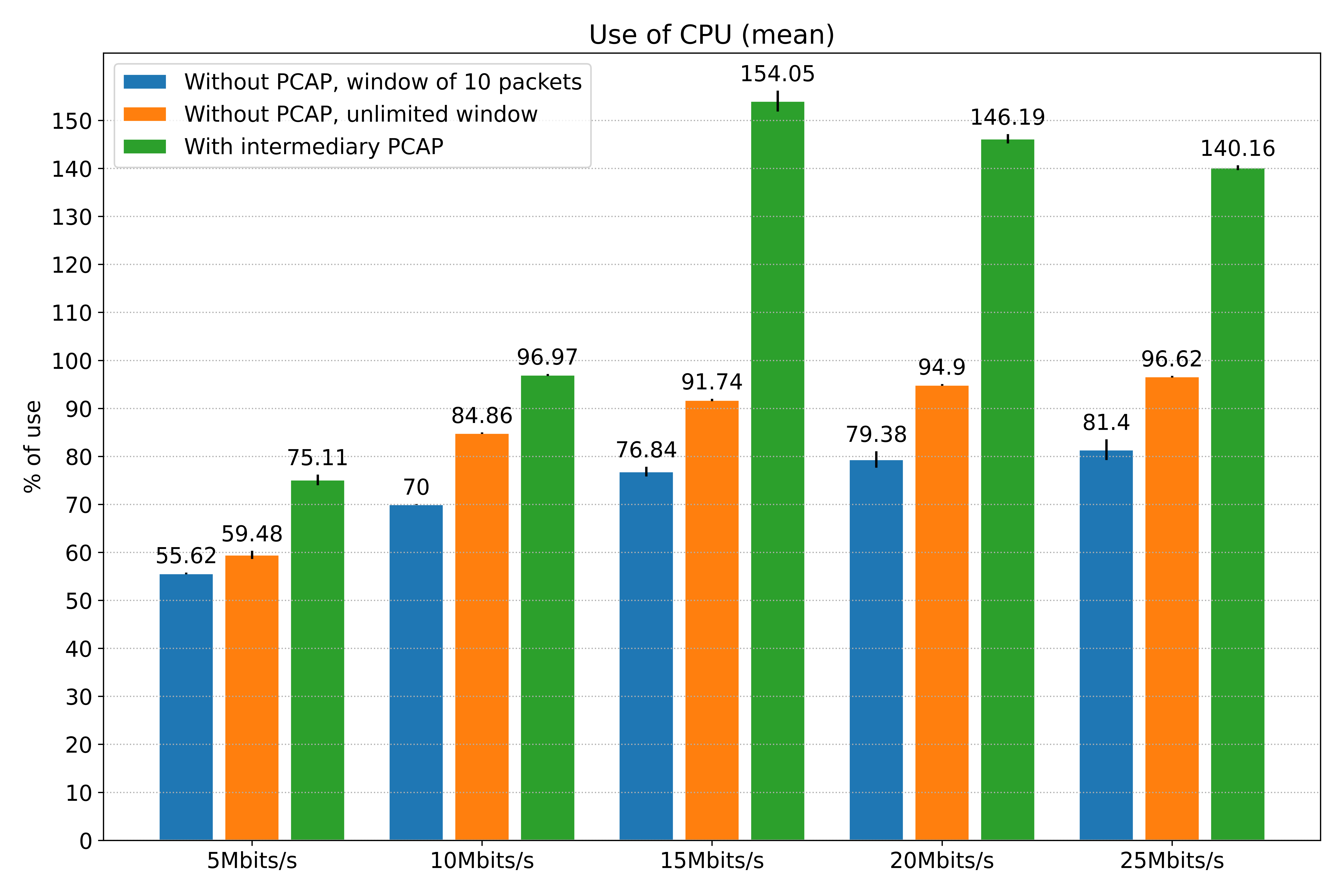
However, this difference in results also comes with a computational cost, as indicated in the next figure. The method that doesn’t use a PCAP intermediary file with an unlimited window is almost as effective as the one that uses the file, but its time of execution in the 25Mbits/s scenario is almost triple in favor of this last one. This is expected: remember that the one with PCAP files benefits from parallelism. This is also perceived in the CPU consumption, but with the opposite effect: the parallelized one uses more than 100% of CPU, given that it’s running on more than one CPU core, while the other is restricted to one core. Even so, the method with a limited window is a way more performant, and also coherent: as the flow increases and the loss is accentuated, its time of execution and CPU consumption reach a plateau.
The memory peak is also interesting to observe: as can be seen in the next graph, the traditional method, even with a higher usage of disk when compared to the other two methods, is the one that uses the highest amounts of this resource. The methods without the use of a PCAP file had a better performance on this metric, with the one that uses a limited window having a considerable advantage when compared to the one with unlimited, presenting a gradual increase a way less expressive as the bit rate increases.
 Memory peak over all the processes in execution.
Memory peak over all the processes in execution.
In this way, in terms of the effectiveness of processing, the reference method that uses an intermediary PCAP file is presented to be the best, as it never loses packets from the network. Our proposal without the PCAP file and unlimited window also presented a low loss of packets. However, limiting the window of packets to be given to the thread responsible for the CSV file resulted in a gain of performance, with a lower time of execution and CPU and memory consumption, but at the cost of packet loss.
Next steps
For the next and final months of research, our discussions have been to focus in applications of AI for our study case, either working on an existing model to perform inference on live network traffic in a distributed manner or trainning/adapting a new model to be able to classify the traffic as benign or malicious, running on a performance limited device. In parallel, we also plan to produce more publications and didactic material with details of the work done so far. In short, these are our plans for now, together with our previous goals according to post 05:
- Packet Parsing
- Conduct experiments to verify the performance of Python libraries sniffing the network and processing the packages in a Raspberry Pi (different from what we did in post 4, in which we tested the lib’s with the CIC-IoT-2023 dataset and in a regular computer).
- [NEW] Study mechanisms for generating CSV files from PCAP ones or directly from live network traffic.
- Inference
- Run the baseline models proposed in post 02 in a Raspberry Pi to verify its performance.
- Perform experiments connecting the packet sniffer to the AI baseline models.
- Training (centralized IDS)
- TBD.
This post was made as a record of the progress of the research project “DDoS Detection in the Internet of Things using Machine Learning Methods with Retraining”, supervised by professor Daniel Batista, BCC - IME - USP. Project supported by the São Paulo Research Foundation (FAPESP), process nº 2024/10240-3. The opinions, hypothesis and conclusions or recommendations expressed in this material are those of the author and do not necessarily reflect the views of FAPESP.