Research checkpoint #13: running the baseline ML models on a more powerful machine
In the last post, I reported the results of performing a DDoS attack against a more powerful machine, understanding the impact on performance and effectiveness of the hardware improvement compared with the Raspberry Pi. Since then, we discussed some details on our experimentation structure and defined our next steps for the final months on the project: study dimensionality reduction techniques, with the goal of running the baseline ML models on the Raspberry Pi, and do some work on distributed inference. In that regard, here we will discuss some experiments on how our more powerful machine handled these ML models used for reference and some ideas on the serialization of the models.
Testing the baseline models with a more powerful machine
In post #06, we evaluated the performance of the Raspberry Pi running two machine learning models: a logistic regression and a Hoeffding Tree, chosen accordingly to previous literature studies. The datasets used for this work were the Pima Indians Diabetes Database and the already known CIC-IoT-2023. However, with this last one, we observed that the Raspberry Pi wasn’t able to complete the experiment in a reasonable time, as it wasn’t capable of handling the volume of data (we were working with 561Mb). As we are now structuring a new phase of experiments with a more powerful computer, in this post I discuss the results of this machine running these same baseline models with these same datasets, training them and performing inference in part of the data, to compare it with what we already achieved and use as a reference.
The computer specifications we used are:
- Intel(R) Core(TM) i7-6700K CPU @ 4.00GHz
- 32GB DDR4 2400 MHz RAM
- Debian GNU/Linux trixie/sid OS
- 1000 Mbits/sec network interface card (Gigabit Ethernet)
The structure of the experiments was the same as the cited post, using the Jupyter Notebooks converted to scripts found here to evaluate the computer with the Pima dataset and the scripts found here when using the CIC one. Our goal wasn’t to evaluate the efficacy of the models, like the accuracy or F1-score, as they are deterministic and reproduced the same metrics from the post with the Raspberry, but to observe the performance values: average time of execution and peak of memory use after 10 repetitions of the experiment.
Testing with the Pima Indians Diabetes dataset
The results observed with the Logistic Regression models were these ones:
| Average time | Peak of memory use |
|---|---|
| 0.7515s | 169816KB (~169MB) |
Table 01: Average time and peak of memory use running a Logistic Regression model with the Pima Indians Diabetes dataset
In the other post, we saw that the Raspberry Pi had an average time of execution of 6.0306s and my notebook of 3.8677s, a significant improvement here! The value observed above is 8x smaller than that of the Raspberry Pi and 5x smaller than my notebook, very significant. However, the memory had a little increase in its value, it isn’t clear for me the reason for that.
This same behavior happened for the experiments with the Hoeffding Tree model:
| Average time | Peak of memory use |
|---|---|
| 0.8888s | 152620KB (~153MB) |
Table 02: Average time and peak of memory use running a Hoeffding Tree model with the Pima Indians Diabetes dataset
Again, we observe a contrast between this value and what we observed in the post #06:
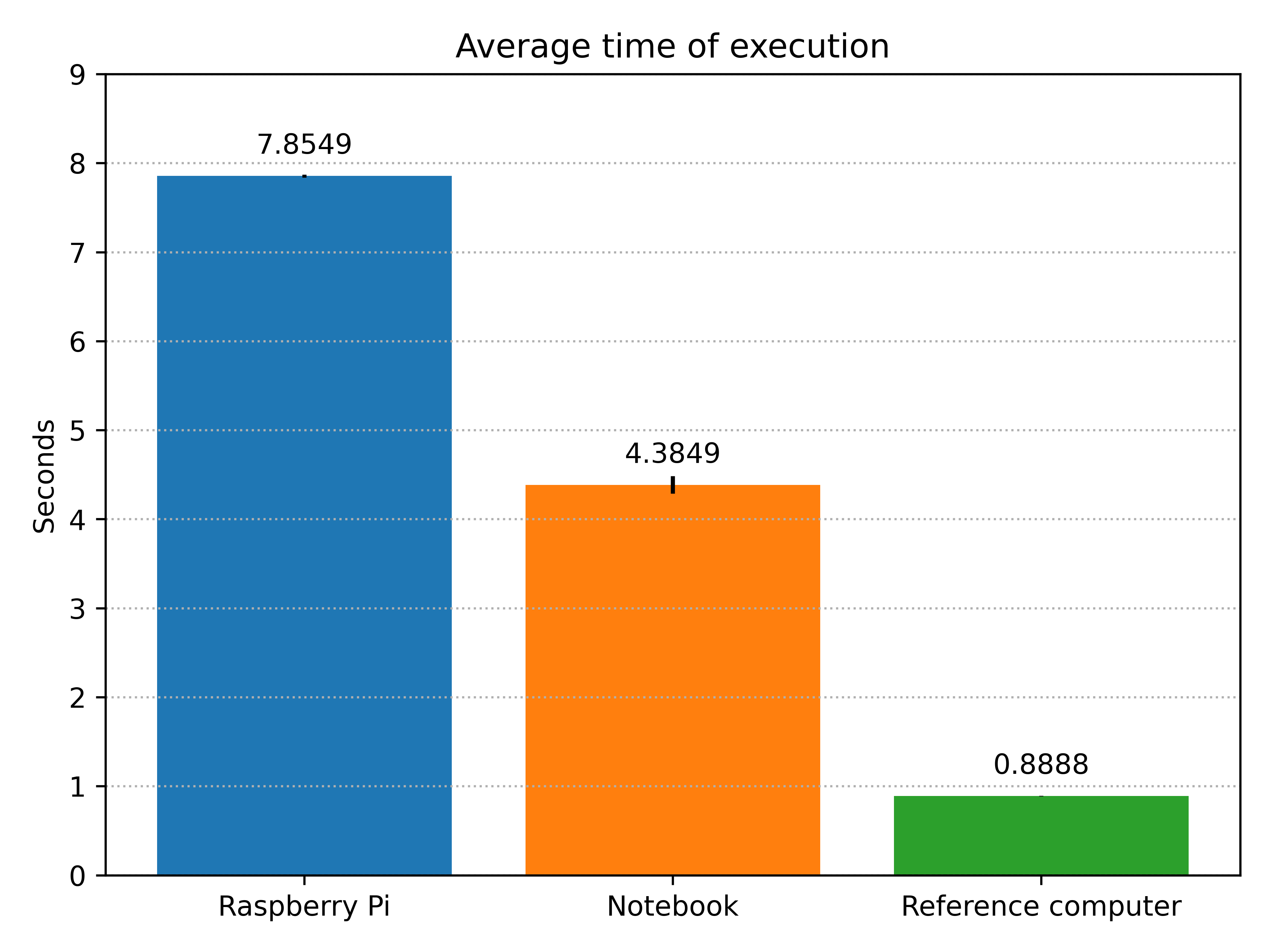 Comparison of the time of execution of the computers from post #06 and the one being evaluated here with the Pima dataset and the Hoeffding Tree model.
Comparison of the time of execution of the computers from post #06 and the one being evaluated here with the Pima dataset and the Hoeffding Tree model.
As one can see visually above, the result is very discrepant, indicating that the improvement of hardware has a significant impact on the final results with this dataset.
Testing with the CIC-IoT-2023 dataset
Following this same procedure, let’s now observe the results of this capable machine with the CIC-IoT-2023 dataset. First, running the Logistic Regression model:
| Average time | Peak of memory use |
|---|---|
| 31.8669s | 1454956KB (~1.45GB) |
Table 03: Average time and peak of memory use running a Logistic Regression model with the CIC-IoT-2023 dataset
Note that the time of execution is much more expressive than the one in Table 03. However, compared against the values observed with my notebook in post #06 (remember that the Raspberry Pi wasn’t able to run the model in a reasonable time), it is still an improvement: we registered 1m3.5792s of average with that other device, twice the value observed here. And almost the same proportion applies to the Hoeffding Tree model:
| Average time | Peak of memory use |
|---|---|
| 16m13.4542s | 1940000KB (1.94GB) |
Table 04: Average time and peak of memory use running a Hoeffding Tree model with the CIC-IoT-2023 dataset
With the notebook, the average time was 32m30.2128s, very close to twice that of the one in Table 04. Again, the use of memory here is a little above the ones in post #06, the reason for that is still not clear. But, considering the total capacity of the machine (32GB), this isn’t very expressive.
Therefore, the improvement in the hardware demonstrated a significant impact. The idea of performing the training of the model on a more capable computer and the inference in a distributed form sounds like a great way to take advantage of the capabilities of a powerful machine and still to not overload it with all the network traffic. But, more experiments have to be done in order to conclude if this technique is viable.
Thinking about how to distribute the inference
In the direction of the last paragraph, how could we perform something like that? How to train the model on a computer and then transfer it to another one? This can be done using object serialization, as described in the “Model Persistence” post of the scikit-learn user guide. The general idea is to transform a Python object into a file and then load it on another computer, like the Raspberry Pi. In this way, we can keep the parameters that we achieved after the training phase and perform only the inference on this other device.
There are some different libraries capable of doing so, one interesting in Joblib, designed to be lightweight and efficient, characteristics that are interesting for us as we are dealing with low-performance devices. Under the hood, it uses the Pickle module, but has specific optimizations for dealing with numpy arrays and, as we are handling ML models, this sounds like a great feature! An implementation example can be found here.
Next steps
In the conclusion of the last post, I stated that our next steps would be to integrate packet sniffing with the baseline AI models to perform the network inference. To achieve this result, we discussed here the performance of these models on a more capable machine, which can serve as a comparative reference, and some ideas on how to decentralize the inference. Considering this, for the next steps, our plan is to:
Apply techniques of dimensionality reduction in the datasets (like Mutual Information and/or PCA) and run models with this smaller dataset on the machines to verify their performance;
Briefly study the performance of doing the training phase on the powerful machine and then the inference on the Raspberry Pi, in a distributed way.
This post was made as a record of the progress of the research project “DDoS Detection in the Internet of Things using Machine Learning Methods with Retraining”, supervised by professor Daniel Batista, BCC - IME - USP. Project supported by the São Paulo Research Foundation (FAPESP), process nº 2024/10240-3. The opinions, hypothesis and conclusions or recommendations expressed in this material are those of the author and do not necessarily reflect the views of FAPESP.